I've gotten a lot of questions all related to the idea of averages, so I'm going to devote the next 3 posts to discussing different facets of averaging. It'll be like a trilogy, but hopefully one more like
Lord of the Rings than
Jurassic Park. Stay tuned to find out!
Dear Dr. Math,
Is there a difference in roulette between betting on black versus betting on a number, like 6? What about betting both at the same time? I usually have more fun betting on black, because my guess is that by betting on black I lose money more slowly, but I'm not sure which is actually better.
Sean
Dear Sean,
My first rule of gambling is don't gamble. (The second rule of gamb.... OK, you get the idea.) But I wouldn't be much of an advice columnist if I told you to do something just because I said so, without helping you understand why. So, maybe after we dissect this gambling question we can talk about why gambling is generally a bad idea. Then we'll talk about why you should sit up straight and why you didn't call me on my birthday.
OK, first: why the bets are the fundamentally the same, and second: why they're different.
The most rudimentary way of analyzing the quality of a bet is computing what's called its
expected value. This is the number you get by multiplying each possible payoff by its probability and adding them all together. In roulette, and most other casino games, both the payoffs and the probabilities are well-known, so the expected value is easy to compute. As a convention, we always compute the expected value for a bet of $1 (my kind of bet), but for you high-rollers who bet $
n, you can just multiply the end result by
n. In the first example, your bet on black, there are 18 ways to win (the 18 black pockets) and 20 ways to lose (the 18 red pockets and the 2 green ones), and we're assuming that every pocket is equally likely, so the probability of winning is

. If you win, you get $2--your original $1 back plus another one from the house. If you lose, which happens with probability

, you get nothing but my condolences, which have no cash value. So altogether your expected value is

, or $0.946. Note that the

wasn't really doing anything in that calculation, so for simplicity we can skip that part from now on.
Now, the bet on 6 has a lower probability of winning but a higher payoff, and as we'll see, the two effects cancel each other out exactly. The payoff for winning a bet on 6 is $36, including your $1 plus $35 of the house's, and the probability of winning is

, since there's only the one 6 on the wheel, as in life. Hence, the expected value of the bet is

again. Those clever French guys in the 18th century managed to design the game of roulette so that almost every bet has that same expected value of $0.946, or 94.6¢. Interestingly enough, in America, there
is actually one bet which is worse--the "5 number" bet on 0, 00, 1, 2, and 3, which has a payoff of $7 and a probability of

, for an expected value of

--but since they don't use a 00 in other places, we Americans have that unique opportunity of actually making a worse decision when playing roulette than just playing roulette in the first place.
The reason the expected value matters so much has to do with something I'm sure I'll be talking a lot about in future entries, The Law of Large Numbers, sometimes mistakenly called the "Law of Averages." Essentially (and pay attention to the words I emphasize for clues about how people misuse it), the LLN says that if you keep making the
same bet over and over again, in the
long run, the total payoff
divided by the total number of bets will converge to the expected value of the bet. So, both your bet on black and your bet on 6 will pay you off $0.946 per bet on average, assuming you have enough chips to hang around and keep betting. Notice that this is a
bad thing for you and a good thing for the house, because the expected value is less than the price to play the game, $1. I remember being surprised when I went to Las Vegas that so many casinos advertise things like "99% payoffs guaranteed," meaning they're guaranteeing that you lose money?
Also, it's worth mentioning that you can't improve the situation by sneakily combining multiple bets or betting different amounts or any of the other so-called "systems". Expected value has the property that you can compute the expected values of each part of an overlapping bet, like 6
and black, separately and then just add them together. In the end, a bet of $1 bet gives you back an average of $0.946 until you simply run out of money and go home.
The difference, then, between the two kinds of bets has to do with something called their
variance, or its square root which goes by the name
standard deviation. I'll spare you the formulas (for now), but essentially variance is a measurement of how "spread out" the payoffs of a bet are. So, among all the bets with the same expected value, the bet with the lowest possible variance, which is 0, is the bet where you just hand over your money. The variance gets higher as the payoff gets higher (and the probability of winning gets lower, in order to keep the expected value the same). In the examples above, the bet on black has a variance of about 1.0 and the bet on 6 has a variance of about 33.2, which is substantially larger.
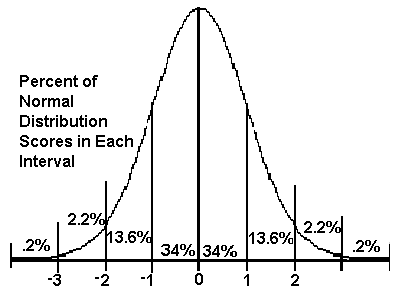
What's going on kind of behind-the-curtain is that over time, if you keep placing the same bet over and over, the
distribution of your accumulated winnings takes the shape of a bell curve (by the
Central Limit Theorem). The mean of that curve is determined by the expected value of each bet (on account of the LLN); how spread out it is depends on the variance. And if you don't want a lot of risk (of losing
or winning), you should try to reduce that spread as much as possible. The casino, for example, would prefer that you just hand over the 5.26 cents you were going to lose on average and repeat. Since that wouldn't be much fun for you, they offer a little variance to keep you entertained. But as you rightly point out, too much variance isn't fun either, because you don't get to "win" very often, and so you might not come back to play again. So it's a delicate balance. Personally, I like the strategy of betting the table minimum on black and red simultaneously and drinking as many free cocktails as possible while my chip stack gradually diminishes. But these are personal decisions.
Bottom line: you can't beat the house, all you can do is maybe make it take a little longer for them to beat you.
-DrM